
در دنیای هوش مصنوعی، مفهومی به نام مدل زبانی بزرگ (LLM) بهسرعت به یکی از اجزای کلیدی فناوریهای نوین تبدیل شده است. شاید با عباراتی مثل GPT یا مدلهای مولد برخورد کرده باشید، اما واقعاً LLM چیست؟ مدلهایی مانند GPT-4، LLaMA یا PaLM توانایی درک و تولید زبان طبیعی را دارند و در ابزارهایی مثل چتباتها، موتورهای جستوجو و سامانههای تحلیل متن استفاده میشوند؛ اما LLM فقط یک تکنولوژی جدید نیست؛ بلکه نقطهعطفی در پردازش زبان طبیعی است. شناخت درست آن میتواند دید تازهای نسبت به مسیر آینده و کاربردهای هوشمند مبتنی بر زبان ایجاد کند؛ در ادامه، نهتنها به تعریف دقیق LLM میپردازیم، بلکه به بررسی ساختار فنی، کاربردهای واقعی، مزایا، چالشها و آیندهای که این فناوری رقم میزند نیز خواهیم پرداخت.
LLM چیست؟
در سالهای اخیر، با رشد سریع هوش مصنوعی، اصطلاحی به نام مدل زبانی بزرگ (LLM) بیش از همیشه شنیده میشود، اما LLM چیست و چرا توجه اینهمه متخصص و فعال حوزه فناوری را به خود جلب کرده است؟
LLM یا Large Language Model نوعی معماری یادگیری ماشین است که با بهرهگیری از شبکههای عصبی پیشرفته (معمولاً مدلهای ترنسفورمر)، میتواند زبان انسان را درک کرده، تولید کند و حتی تحلیل مفهومی از آن ارائه دهد.
این مدلها با تحلیل میلیاردها کلمه از منابع متنی متنوع، قابلیتهایی فراتر از درک واژگان پیدا میکنند؛ آنها مفهوم، زمینه و ساختار زبان را میآموزند. در واقع، LLMها پایهایترین عنصر در بسیاری از سیستمهای هوشمند امروزی هستند؛ از چتباتهایی مثل ChatGPT گرفته تا موتورهای جستوجو و سامانههای تحلیل متن. برخلاف مدلهای سنتی NLP، این مدلها مقیاسپذیرتر، منعطفتر و عمیقتر هستند. برای اینکه درک دقیقتری از LLM پیدا کنیم، ابتدا باید بدانیم این اصطلاح از کجا آمده و چه مفهومی پشت آن قرار دارد:
LLM مخفف چیست؟
عبارت LLM مخفف Large Language Model است. ترجمه تحت اللفظی آن میشود «مدل زبانی بزرگ»؛ اما این تعریف ساده، عمق عملکرد آن را نشان نمیدهد. در اینجا منظور از “Large”، تنها حجم دادهها یا تعداد پارامترهای مدل نیست؛ بلکه به ظرفیت پردازش زبان، پوشش حوزههای مختلف دانشی و قابلیت تعمیم مدل به وظایف متنوع اشاره دارد؛ در ترکیب این عبارت:
- Language Model به مدلی اشاره دارد که میتواند توالیهای زبانی را پیشبینی و تولید کند.
- Large یعنی این توانایی در مقیاس بسیار گسترده، با پارامترهای میلیاردی، و روی دیتاستهایی در حد ترابایت آموزش داده شده.
📑
جزئیات بیشتر درباره پیادهسازی مدلهای زبانی در چارچوب پروژه هوش مصنوعی در نیک آموز!📑
تعریف Llm در هوش مصنوعی
برای درک بهتر جایگاه LLM در هوش مصنوعی، باید ابتدا بفهمیم که هوش مصنوعی کلاسیک در زمینه پردازش زبان، چه محدودیتهایی داشته است و چرا مدلهای زبانی بزرگ بهعنوان نقطه عطف شناخته میشوند. درگذشته، ابزارهای زبانپرداز (NLP) بیشتر مبتنی بر قواعد دستنویس یا مدلهای آماری ساده بودند. این ابزارها میتوانستند برخی الگوهای زبانی را تشخیص دهند، اما درک واقعی از معنا، زمینه یا هدف جمله نداشتند؛ اینجا بود که نیاز به یک مدل هوشمندتر، عمیقتر و سازگارتر با زبان طبیعی احساس شد.
مدلهای زبانی بزرگ (LLM) این خلا را پر کردند؛ در واقع، LLM در هوش مصنوعی به مدلی گفته میشود که توانایی یادگیری زبان طبیعی را با استفاده از شبکههای عصبی عمیق دارد. این مدلها نهتنها از دادههای متنی وسیع (کتابها، وبسایتها، مقالات علمی و…) تغذیه میشوند، بلکه میتوانند الگوهای پیچیده زبان را استخراج کرده، بین مفاهیم ارتباط برقرار کنند و محتوا تولید نمایند؛ یکی از مهمترین دستاوردهای LLM در AI این است که:
- بدون نیاز به برنامهنویسی صریح یا دستورالعملهای مشخص، میتواند سوالات را بفهمد، متن را خلاصه کند، مقاله بنویسد یا مکالمه برقرار کند.
بهعبارت دیگر، LLMها از دسته مدلهای «پیشآموزشدیده» هستند که میتوان آنها را به راحتی برای کاربردهای تخصصی مختلف در هوش مصنوعی شخصیسازی کرد.
این ویژگی، LLM را به یک زیرساخت کلیدی برای توسعه سامانههای هوشمند مدرن تبدیل کرده است؛ بنابراین، اگر بخواهیم ساده و دقیق بگوییم: LLM در هوش مصنوعی، پلی است بین زبان انسان و توانایی ماشین در فهم، پردازش و تعامل با آن.
LLM چطور کار میکند؟
برای درک عملکرد مدلهای زبانی بزرگ (LLM)، باید ابتدا بفهمیم این مدلها دقیقاً چگونه «یاد میگیرند» و چطور میتوانند زبان انسان را تولید و درک کنند. در سادهترین بیان، LLMها نوعی از مدلهای یادگیری عمیق هستند که بر اساس ساختارهای توالیمحور طراحی شدهاند. آنها با تحلیل حجم عظیمی از دادههای متنی، الگوهای آماری زبان را یاد میگیرند. اما برخلاف مدلهای قدیمی که فقط توالی واژهها را پیشبینی میکردند، LLMها میتوانند:
- وابستگیهای طولانی بین واژهها را تشخیص دهند،
- مفهوم جمله را در زمینههای مختلف درک کنند،
- خروجیهایی تولید کنند که طبیعی، معنادار و حتی خلاقانه باشند.
اما این قابلیتهای پیچیده چطور ممکن شدهاند؟ پاسخ در ساختار درونی آنهاست؛ یعنی معماری Transformer.
ساختار فنی LLMها (Transformer و Attention)
Transformer، که اولینبار در مقاله معروف “Attention is All You Need“ توسط گوگل معرفی شد، معماری پایهای بیشتر LLMهای مدرن است (از جمله GPT، BERT، T5 و …). در قلب این معماری، مفهومی به نام Attention Mechanism قرار دارد.
برخلاف مدلهای قبلی که دادهها را به ترتیب پردازش میکردند (مثل RNN یا LSTM)، ترنسفورمرها میتوانند بهصورت موازی کار کنند و در هر لحظه، به تمام بخشهای ورودی توجه کنند.
چگونه Attention کار میکند؟
مکانیزم Attention به مدل اجازه میدهد تعیین کند که هر واژه در یک جمله، چقدر باید روی واژههای دیگر تمرکز کند. مثلاً وقتی مدل جملهای مثل «او کتاب را خواند چون خسته بود» را میبیند، باید بفهمد که «او» به «خسته» ربط دارد، نه «کتاب». این ارتباطات معنایی دقیق، با کمک Attention شناسایی میشود.
از یادگیری به تولید محتوا
LLMها ابتدا روی یک مجموعه بزرگ از متون (مثلاً کل وب یا کتابخانههای عمومی) بهصورت پیشآموزش (Pre-training) آموزش میبینند؛ سپس میتوان آنها را برای کاربرد خاصی تنظیم نهایی (Fine-tune) کرد — مثلاً برای نوشتن گزارش مالی، پاسخ به سؤالات پزشکی، یا تحلیل دادههای مشتریان.
چرا Transformer مهم است؟
- مقیاسپذیری بالا: چون بهصورت موازی اجرا میشود، میتواند سریعتر آموزش ببیند.
- حفظ ارتباطات معنایی بلندمدت: حتی بین واژههایی که فاصله زیادی از هم دارند.
- امکان پیشآموزش روی دادههای عمومی و فاینتیون روی دادههای خاص.
کاربردهای LLM در دنیای واقعی
طیف گستردهای از سرویسها و محصولات دیجیتال امروزی، بهشکل مستقیم یا غیرمستقیم از LLM بهره میبرند. در ادامه به مهمترین کاربردهای عملی این مدلها در صنایع مختلف اشاره میکنیم:
چتباتها و دستیارهای هوشمند (مثل ChatGPT)
یکی از ملموسترین نمونههای استفاده از LLM، توسعه چتباتهای پیشرفته و دستیارهای مکالمهمحور است. مدلهایی مانند GPT به چتباتها این امکان را میدهند که نهتنها پاسخهایی از پیش تعریفشده بدهند، بلکه با زبان طبیعی انسان، تعامل کنند، مکالمه را درک کنند و پاسخهای متنی کاملاً سازگار با زمینه بدهند؛ برخلاف چتباتهای قدیمی که محدود به الگوهای ساده بودند، LLMها میتوانند:
- مکالمه را در چند مرحله پیگیری کنند،
- سوالات باز یا چندلایه را تحلیل کنند،
- و پاسخهایی دقیق، منعطف و طبیعی ارائه دهند.
این فناوری اکنون در بسیاری از پلتفرمهای خدمات مشتری، سامانههای پشتیبانی، دستیارهای درونسازمانی و حتی اپلیکیشنهای آموزشی بهکار گرفته شده است.
تولید متن، خلاصهسازی و ترجمه
یکی دیگر از کاربردهای برجسته LLMها، تولید و بازنویسی محتوای متنی است. این مدلها میتوانند با درک ساختار و معنای متن، عملیاتهایی نظیر:
- تولید مقاله، گزارش یا محتوای بازاریابی
- خلاصهسازی متون بلند به نسخههای کوتاه و قابلاستفاده
- ترجمه متون از زبانی به زبان دیگر با حفظ مفهوم و سبک بیان
را انجام دهند. آنچه LLMها را در این حوزه متمایز میکند، توانایی درک زمینه و سازگاری با لحن متن است. مثلاً میتوان از آنها خواست گزارشی فنی را به زبان سادهتری برای مدیران غیرتخصصی بازنویسی کنند.
استفاده در حوزههای پزشکی، حقوق و آموزش
کاربرد LLMها فقط به حوزههای عمومی محدود نمیشود. این مدلها در صنایع تخصصی نیز نقش کلیدی دارند.
- در پزشکی، LLMها میتوانند گزارشهای بالینی را خلاصه کرده، راهنمای دارویی ارائه دهند، یا به پزشکان در تشخیص اولیه کمک کنند.
- در حقوق، این مدلها در تحلیل قراردادها، طبقهبندی پروندهها یا ارائه پیشنویس اسناد حقوقی کاربرد دارند.
- در آموزش، میتوان از آنها برای طراحی محتوای آموزشی، ایجاد تمرینهای تعاملی یا پاسخگویی به سوالات دانشجویان استفاده کرد.
نکته مهم این است که LLMها در این کاربردها نهتنها وظایف انسانی را تقلید نمیکنند، بلکه میتوانند نقش مکملی داشته باشند: افزایش بهرهوری، کاهش خطای انسانی، و سرعتبخشی به پردازشهای اطلاعاتی.
تفاوت LLM با دیگر مدلهای زبانی
مدلهای زبانی سالهاست در قلب فناوریهای پردازش زبان طبیعی (NLP) حضور دارند. اما با ظهور LLMها یا همان مدلهای زبانی بزرگ، یک تحول عمیق مفهومی و فنی در این حوزه رخ داده است. در نگاه اول ممکن است LLM تنها نسخهای بزرگتر از مدلهای قبلی بهنظر برسد، اما در واقع تفاوتهایی بنیادین وجود دارد که آنها را وارد کلاس کاملاً جدیدی از مدلها میکند.
تفاوت LLM با NLP سنتی
در اینجا نگاهی دقیقتر میاندازیم به مهمترین تفاوتهای میان مدلهای زبانی بزرگ (LLM) و سیستمهای سنتی پردازش زبان طبیعی (Traditional NLP):
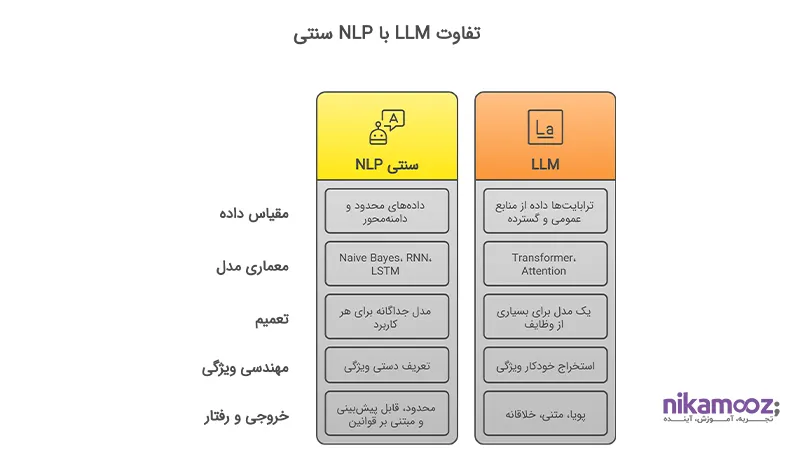
- ابعاد و مقیاس دادهها
- NLP سنتی: معمولاً بر مبنای مجموعه دادههای محدود و دامنهمحور آموزش میبیند.
- LLM: بر پایه ترابایتها داده از منابع گسترده عمومی آموزش داده میشود و میتواند برای دامنههای خاص فاینتیون شود.
- معماری مدل
- NLP سنتی: معماریهایی مانند Naive Bayes، RNN یا LSTM را بهکار میبرد که در درک وابستگیهای دوربین واژهها ضعیفاند.
- LLM: از Transformer و Attention استفاده میکند که قادر به درک وابستگیهای طولانی و معنایی عمیق هستند.
- قابلیت تعمیم (Generalization)
- NLP سنتی: برای هر کاربرد نیاز به مدل جداگانه دارد.
- LLM: یک مدل میتواند طیف وسیعی از وظایف را انجام دهد، از پاسخ به سوال تا ترجمه و تولید محتوا.
- نیاز به تنظیم دستی ویژگیها
- NLP سنتی: ویژگیها (Features) معمولاً بهصورت دستی تعریف میشوند.
- LLM: ویژگیها بهصورت خودکار و از دل داده استخراج میشوند (Representation Learning).
- خروجی و رفتار مدل
- NLP سنتی: خروجیها معمولاً محدود، قابلپیشبینی و مبتنی بر قواعد ثابت هستند.
- LLM: خروجیها پویا، وابسته به زمینه، و گاه حتی خلاقانه هستند.
مزایای مدلهای LLM
مدلهای زبانی بزرگ (LLM) با رشد چشمگیر خود در سالهای اخیر، توانستهاند جایگاه ویژهای در زیرساختهای هوش مصنوعی بهدست آورند. اما دقیقاً چه چیزی آنها را تا این حد ارزشمند کرده است؟
درک زبان با عمق و دقت بالا
یکی از برجستهترین مزایای LLMها توانایی درک واقعی زبان انسان است — نه فقط تشخیص واژهها، بلکه درک مفاهیم، زمینه، وابستگی معنایی و حتی نیت جمله. این قابلیت باعث میشود LLMها بتوانند محتوایی تولید کنند که طبیعی، قابل فهم و دقیق است؛ از پاسخگویی در گفتوگو گرفته تا تحلیل اسناد و تولید گزارش.
عملکرد چندمنظوره در وظایف مختلف زبانی
برخلاف مدلهای سنتی که برای هر وظیفه نیاز به آموزش جداگانه داشتند، یک LLM میتواند بهصورت همزمان در چندین وظیفه زبانی فعالیت کند: ترجمه، خلاصهسازی، پرسش و پاسخ، تکمیل متن، بازنویسی، تحلیل معنا و … این مزیت نه تنها توسعه سیستمها را سریعتر میکند، بلکه هزینه نگهداری و پیچیدگی زیرساختها را نیز کاهش میدهد.
یادگیری بدون نظارت و کاهش نیاز به برچسبگذاری داده
LLMها معمولاً با یادگیری خودنظارتی (Self-Supervised Learning) آموزش داده میشوند، یعنی نیازی به دادههای برچسبخورده ندارند. این ویژگی به آنها امکان میدهد تا از دادههای خام، گسترده و عمومی یاد بگیرند — و سپس برای حوزههای خاص تنظیم شوند؛ نتیجه؟ انعطافپذیری بالا، کاهش زمان آمادهسازی دادهها، و توسعه سریعتر راهکارهای هوش مصنوعی.
مقیاسپذیری در آموزش و اجرا
مدلهای LLM با بهرهگیری از معماری Transformer، میتوانند بهصورت موازی آموزش ببینند و در مقیاسهای مختلف اجرا شوند. این ویژگی باعث میشود هم در محیطهای بزرگ پردازشی قابل استفاده باشند و هم در نسخههای کوچکتر برای استفاده در دستگاههای سبک یا برنامههای لبهای (Edge-based).
شخصیسازی و تنظیم برای کاربردهای خاص
یکی از مزیتهای کلیدی LLMها توانایی تنظیم مجدد (Fine-tuning) برای سناریوهای خاص است؛ مثلاً میتوان یک مدل عمومی را برای تحلیل اسناد حقوقی، گفتوگوی پزشکی، یا تولید محتوای بازاریابی با دادههای متنی مرتبط تنظیم کرد — بدون نیاز به ساخت مدل از صفر.
چالشها و محدودیتهای LLMها
با وجود تمام توانمندیها و دستاوردهای چشمگیر، مدلهای زبانی بزرگ (LLM) بدون محدودیت نیستند. در واقع، هرچقدر مقیاس و قدرت این مدلها بیشتر میشود، پیچیدگیها و دغدغههای فنی، اخلاقی و عملیاتی نیز پررنگتر میشوند.

هزینههای محاسباتی سنگین
یکی از اصلیترین چالشها، نیاز شدید به منابع سختافزاری قدرتمند است. آموزش یک LLM در مقیاس GPT-3 یا GPT-4 به دهها هزار GPU، هفتهها زمان پردازش و انرژی بسیار زیادی نیاز دارد. حتی اجرای inference (پاسخگویی یا تولید متن) نیز ممکن است روی دستگاههای معمولی بهینه نباشد، مگر با کمک زیرساختهای ابری پیشرفته. این مسئله، بهرهگیری گسترده از LLMها را برای بسیاری از کسبوکارها یا نهادهایی که زیرساخت محدود دارند، با چالش مواجه میکند.
عدم شفافیت و قابلیت توضیحپذیری پایین
LLMها، مانند بسیاری از مدلهای یادگیری عمیق، جعبهسیاه (Black Box) محسوب میشوند. یعنی در بسیاری از موارد نمیتوان با دقت گفت چرا مدل تصمیم خاصی گرفته یا پاسخی خاص تولید کرده است. در حوزههایی مثل پزشکی، حقوق یا تصمیمسازی سازمانی که شفافیت، ردیابی و پاسخگویی بسیار مهماند، این ویژگی میتواند یک ریسک محسوب شود.
خطر سوگیری (Bias) در دادهها
LLMها از دادههای عظیم عمومی آموزش میبینند که اغلب بدون کنترل یا پالایش کامل هستند. این موضوع باعث میشود مدل ممکن است سوگیریهای نژادی، جنسیتی، فرهنگی یا سیاسی را از دادهها یاد بگیرد و بهطور ناخواسته بازتولید کند. اگر این مدلها در سیستمهایی با تصمیمگیری واقعی استفاده شوند (مثلاً استخدام، نمرهدهی یا توصیهگرها)، میتوانند پیامدهای جدی به همراه داشته باشند.
احتمال تولید اطلاعات نادرست یا گمراهکننده
یکی از رفتارهای شناختهشده LLMها، تولید پاسخهایی است که از نظر زبانی کاملاً درست بهنظر میرسند، اما از نظر محتوایی نادرست یا جعلیاند. به این پدیده “Hallucination” گفته میشود. این مشکل بهویژه در کاربردهای حیاتی مثل پاسخ به سوالات تخصصی یا تولید گزارشهای تحلیلی، میتواند خطرناک باشد و نیاز به مکانیزمهای نظارتی یا تأیید انسانی دارد.
مسائل مربوط به حریم خصوصی و امنیت داده
اگرچه LLMها آموزشدیده هستند و بهصورت مستقیم دادهای ذخیره نمیکنند، اما همچنان خطر نشت اطلاعات، بازیابی غیرمجاز از دادههای آموزشی یا سوءاستفاده از مدلهای متنباز وجود دارد. در سناریوهای حساس یا سازمانی، این مسئله باید با دقت ویژه بررسی شود.
مدلهای معروف LLM
در سالهای اخیر، چند مدل زبانی بزرگ بهعنوان رهبران اصلی این فناوری در جهان شناخته شدهاند.
هرکدام از این مدلها توسط یک شرکت بزرگ فناوری توسعه یافته و ویژگیها، اهداف و معماری خاص خود را دارند.
مدل GPT-4 (OpenAI)
GPT-4 نسل چهارم از سری مدلهای Generative Pre-trained Transformer است که توسط OpenAI عرضه شده. این مدل، یکی از پیشرفتهترین LLMهای عمومی دنیاست که در پاسخگویی، تولید متن، خلاصهسازی، ترجمه، و تعامل چندزبانه دقت بالایی دارد. GPT-4 بر پایه معماری Transformer و با استفاده از میلیاردها داده متنی آموزش دیده است. ویژگی خاص آن، توانایی درک پیچیدهتر زمینه، پاسخهای کمخطاتر نسبت به نسخههای قبلی و پشتیبانی از تعاملهای طولانیمدت در مکالمات است.
مدل LLaMA (Meta)
LLaMA (مخفف: Large Language Model Meta AI) یکی از پروژههای متنباز و بسیار انعطافپذیر Meta است. این مدل با هدف ایجاد یک زیرساخت LLM سبکتر، کمهزینهتر و قابل استفاده برای پژوهشگران طراحی شده. LLaMA در چندین نسخه با مقیاسهای متفاوت عرضه شده و بهدلیل حجم کمتر نسبت به GPT، گزینه مناسبی برای استفاده در محیطهایی با منابع سختافزاری محدود یا نیازهای خاص تحقیقاتی محسوب میشود.
مدل PaLM (Google)
(Pathways Language Model) یکی از پروژههای پیشرفته Google در حوزه LLMهاست که بر پایه سیستم آموزشی Pathways این شرکت بنا شده. هدف PaLM ارائه مدلی است که بتواند یادگیری چندوظیفهای، تعامل چندوجهی (متن، تصویر و…) و شخصیسازی بهتر را فراهم کند. نسخههای اخیر PaLM مانند Gemini نیز با معماری بهبودیافته و قابلیت اتصال به سرویسهای مختلف گوگل معرفی شدهاند؛ این مدلها معمولاً به شکل ترکیبی در خدمات گوگل، مانند Workspace یا جستوجوی هوشمند، بهکار گرفته میشوند.
مدل BERT (Google)
(Bidirectional Encoder Representations from Transformers) یکی از مهمترین مدلهای انقلابی در NLP بود که در سال ۲۰۱۸ معرفی شد و نقطه عطفی در فهم زبان طبیعی ایجاد کرد. برخلاف مدلهایی که فقط از چپ به راست یا راست به چپ متن را تحلیل میکردند، BERT از هر دو جهت بهصورت همزمان ساختار جمله را درک میکرد. این قابلیت باعث شد که در بسیاری از وظایف NLP مانند درک پرسش، دستهبندی متن و تحلیل احساسات عملکرد بسیار بهتری نسبت به نسلهای قبل داشته باشد. اگرچه BERT امروزه در دسته LLMهای بسیار بزرگ قرار نمیگیرد، اما بهعنوان مبنای بسیاری از مدلهای مدرن زبانی و الگویی برای طراحی ساختارهای جدید همچنان اهمیت زیادی دارد.
آینده LLM و مسیر پیش رو
مدلهای زبانی بزرگ (LLM) حالا دیگر یک فناوری نوظهور نیستند — بلکه به یکی از ارکان اصلی آیندهی هوش مصنوعی تبدیل شدهاند؛ همانطور که رایانش ابری یا اینترنت اشیا مسیر تحول دیجیتال را در دهههای اخیر تغییر دادند، انتظار میرود LLMها در دههی پیشرو نقش مرکزی در هوش مصنوعی عمومی (AGI)، اتوماسیون شناختی و تصمیمسازی هوشمند ایفا کنند. روندهای جهانی نشان میدهد LLMها به سمت قابلیتهای ترکیبی در حرکتاند:
- چندوجهی شدن (Multimodal): ترکیب متن با تصویر، صدا و ویدیو در یک مدل واحد (مثل GPT-4V یا Gemini)
- عاملمحور شدن (Agent-based AI): اتصال LLM به ابزارها، APIها و حافظه برای اجرای خودکار وظایف پیچیده
- محلیسازی و شخصیسازی: توانایی انطباق با زبان، سبک و نیازهای خاص کاربران یا سازمانها
- افزایش شفافیت و توضیحپذیری (Explainability): برای حل یکی از بزرگترین چالشهای فعلی یعنی Black Box بودن مدلها
آینده LLM در ایران
در ایران، با وجود برخی محدودیتها در دسترسی به زیرساختهای پردازشی یا مدلهای بینالمللی، علاقهمندی به توسعه LLM بهسرعت در حال رشد است. چند مسیر عملی و قابلتوسعه در این فضا دیده میشود:
- ساخت مدلهای زبانی بومی با تمرکز بر زبان فارسی: پروژههایی مانند “پارسنویسا”، “Baleen” و “Ziya” گامهایی اولیه در این مسیر هستند.
- استفاده از LLMهای متنباز و فاینتیون آنها برای کاربردهای خاص داخلی: بهخصوص در حوزههایی مثل خدمات مشتری، تحلیل اسناد، ترجمه ماشینی، و هوش تجاری.
- یکپارچهسازی LLM با ابزارهای داخلی سازمانها برای ارتقای بهرهوری تیمهای پشتیبانی، تولید محتوا، یا آموزش منابع انسانی.
اما آینده LLM در ایران، وابسته به چند عامل کلیدی است:
- دسترسی پایدار به منابع محاسباتی (GPU و زیرساختهای ابری)
- همکاری میان بخش دولتی، دانشگاهی و خصوصی
- توسعه استانداردهای اخلاقی، امنیتی و قانونی متناسب با استفاده از مدلهای زبانی بزرگ
با توجه به رشد سریع اکوسیستم فناوری کشور، اگر این موانع بهدرستی مدیریت شوند، ایران میتواند سهم فعالی در توسعه کاربردهای بومی LLM داشته باشد — نه صرفاً بهعنوان مصرفکننده، بلکه بهعنوان تولیدکننده راهحلهای هوشمند متنی.
سخن پایانی
در این مقاله بررسی کردیم که LLM چیست، چطور کار میکند، چه ویژگیهایی دارد و در کجاهای واقعی بهکار میرود. از ساختار فنی تا مزایا، محدودیتها و مدلهای برجسته جهانی، مشخص شد که LLM دیگر یک فناوری آزمایشگاهی نیست، بلکه به زیرساختی حیاتی در مسیر پردازش هوشمند زبان انسانی تبدیل شده است. این مدلها میتوانند محتوا را درک، تحلیل و تولید کنند و در بسیاری از سیستمهای نوین نقش تصمیمیار ایفا نمایند. اما بهرهبرداری مؤثر از آنها نیازمند نگاهی دقیق به ظرفیتها، چالشها و مسیرهای توسعه بومی یا جهانی است. اگر در فکر ورود به دنیای LLM هستید (ز مرحله ارزیابی تا پیادهسازی) این مقاله میتواند نقطه آغاز مناسبی باشد. در صورتی که به دنبال راهکارهای حرفهای و قابلاعتماد برای کسبوکار خود هستید، همکاری با نیک آموز میتواند نقطه شروع تحول باشد.
سوالات متداول LLM چیست؟
1. LLM یعنی چی؟
LLM مخفف عبارت Large Language Model یا مدل زبانی بزرگ است؛ این مدلها با استفاده از شبکههای عصبی و دادههای متنی عظیم آموزش میبینند تا بتوانند زبان انسان را بفهمند، پردازش کنند و تولید نمایند. LLMها امروزه در قلب بسیاری از ابزارهای هوشمند مثل چتباتها، مترجمها، موتورهای جستوجو و سیستمهای تحلیل متن قرار دارند.
2. چه تفاوتی بین GPT و LLM وجود دارد؟
GPT یکی از معروفترین مدلهای LLM است که توسط OpenAI توسعه یافته؛ در واقع، GPT زیرمجموعهای از مدلهای زبانی بزرگ محسوب میشود. هر GPT یک LLM هست، اما هر LLM الزاماً GPT نیست. مدلهایی مانند PaLM (گوگل) یا LLaMA (متا) هم نمونههایی از LLM هستند که توسط شرکتهای مختلف ساخته شدهاند.
3. آیا LLM جایگزین NLP سنتی شده است؟
در بسیاری از موارد، بله؛ LLMها بهدلیل دقت بالا، درک زمینه و توانایی یادگیری گسترده، جایگزین روشهای سنتی پردازش زبان طبیعی (مثل RNN یا مدلهای آماری) شدهاند. با این حال، در برخی کاربردهای خاص، ترکیب LLM با روشهای کلاسیک یا قوانین دستنویس هنوز رایج است — بهویژه در سیستمهایی که به توضیحپذیری بالا نیاز دارند.
4. آیا استفاده از LLM در ایران ممکن است؟
بله، اما با محدودیتهایی؛ اگرچه دسترسی به برخی مدلهای بینالمللی محدود است، اما امکان استفاده از LLMهای متنباز مانند LLaMA، BLOOM یا نسخههای سبکتر GPT وجود دارد. همچنین برخی تیمهای داخلی در حال توسعه مدلهای زبانی فارسی یا سازگار با نیازهای بومی هستند.
5. آیا LLMها همیشه پاسخ درست میدهند؟
خیر؛ یکی از چالشهای جدی LLMها پدیدهای به نام Hallucination است، یعنی تولید پاسخهایی که از نظر زبانی درستاند، اما از نظر محتوایی اشتباه یا گمراهکنندهاند. به همین دلیل، استفاده از LLM در کاربردهای حساس نیازمند نظارت انسانی و بررسی صحت خروجیهاست.