در دنیای امروز که مدلهای زبانی بزرگ (LLM) با سرعتی خیرهکننده در حال گسترشاند، نیاز به راهکاری برای افزایش دقت و کاهش خطاهای آنها بیش از پیش احساس میشود. معماری RAG یا Retrieval-Augmented Generation پاسخی نوآورانه به همین نیاز است. اگر به دنبال این هستید که بدانید RAG چیست، چگونه عمل میکند و چرا بهعنوان یکی از موثرترین روشها برای کاهش hallucination در مدلهای زبانی شناخته میشود، این مقاله برای شماست. در اینجا با مفاهیمی مانند retriever و generator، نحوه اتصال RAG به پایگاههای دانش، و نقش آن در ایجاد پاسخهای دقیق آشنا خواهید شد. در ادامه، ضمن بررسی معماری RAG، مزایا، محدودیتها، کاربردهای واقعی و تفاوت آن با روشهای سنتی مانند fine-tuning را نیز مرور میکنیم. این مقاله تلاش میکند تا تصویری دقیق و قابلدرک از جایگاه RAG در توسعه سیستمهای هوشمند ارائه دهد.
RAG چیست؟
برای پاسخ به سوال RAG چیست؟ باید ابتدا به ساختار و هدف اصلی این معماری اشاره کرد. RAG رویکردی پیشرفته در حوزه یادگیری ماشین و پردازش زبان طبیعی (NLP) است که ترکیبی از دو بخش کلیدی را ارائه میدهد: بازیابی اطلاعات (retrieval) از منابع خارجی، و تولید پاسخ (generation) با استفاده از مدلهای زبانی. این معماری برای حل یکی از چالشهای اساسی LLMها یعنی تولید پاسخهای نادقیق یا غیرمستند طراحی شده است. در روشهای سنتی، مدلهای زبانی پاسخهایی را فقط بر اساس دانشی که در زمان آموزش دیدهاند تولید میکنند. اما RAG با افزودن قابلیت اتصال به منابع اطلاعاتی بیرونی، مانند پایگاه داده، اسناد سازمانی یا APIهای جستجو، این محدودیت را برطرف میکند. در نتیجه، خروجی نهایی نهتنها دقیقتر، بلکه مرتبطتر با واقعیت و قابل استناد خواهد بود.
📑
جزئیات بیشتر درباره پیادهسازی مدلهای زبانی در چارچوب پروژه هوش مصنوعی در نیک آموز! 📑
RAG مخفف چیست؟
این واژه مخفف عبارت Retrieval-Augmented Generation است. بهزبان ساده، مدلی است که قبل از تولید پاسخ، ابتدا اطلاعات مرتبط را جستجو کرده و سپس پاسخ را بر اساس همان اطلاعات تولید میکند. این فرآیند دو مرحلهای موجب میشود که خروجی مدل نهفقط زاییده حافظهاش، بلکه بر پایه دانش بهروز و زمینهمند باشد.
مزایای استفاده از RAG در کاربردهای واقعی
معماری RAG با هدف پاسخ به نیازهای پیچیدهتر و دقیقتر در تولید محتوا، گامی بلند در ارتقای مدلهای زبانی محسوب میشود. استفاده از آن در سیستمهای پیشرفته پردازش زبان، مزایای قابلتوجهی به همراه دارد؛ بهویژه زمانی که تصمیمگیریها نیازمند دادههای واقعی، دقیق و تفسیرپذیر باشند.
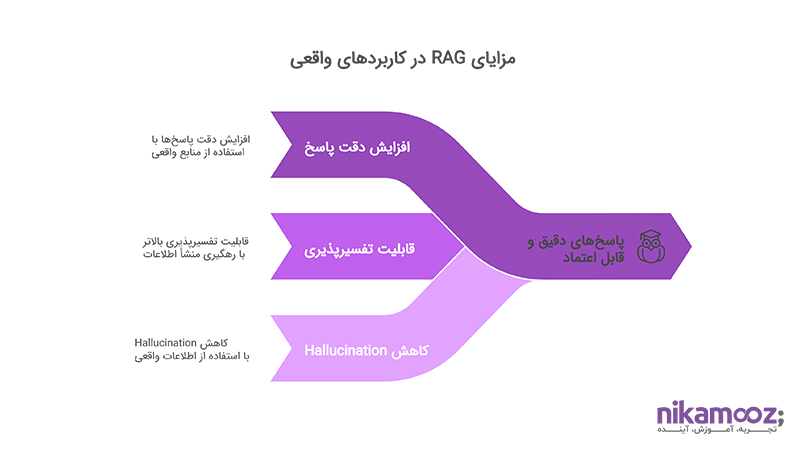
افزایش دقت پاسخها در مدلهای زبانی بزرگ
مدلهای زبانی بزرگ (LLM) معمولاً محدود به اطلاعاتی هستند که در زمان آموزش در آنها ذخیره شده است. RAG این محدودیت را با افزودن ماژول بازیابی اطلاعات از بین میبرد. در این معماری، مدل بهجای اتکا صرف به حافظه درونیاش، از منابع واقعی و ساختیافته برای پاسخدهی استفاده میکند. نتیجه این فرآیند، تولید پاسخهایی دقیقتر، بهروزتر و متناسبتر با زمینه درخواست است. در فضای تصمیمسازی، این دقت بالا میتواند عامل تعیینکننده در پذیرش یا رد یک راهکار باشد.
📑
مطالعه بیشتر 👈 داده کاوی چیست؟ از تعریف تا کاربردهای عملی 📑
قابلیت تفسیرپذیری بالاتر نسبت به LLMهای بدون اتصال به داده
یکی از چالشهای رایج در استفاده از LLMها، عدم شفافیت در منبع تولید پاسخها است. RAG با سازوکار retrieval-based خود، امکان رهگیری منشأ اطلاعات را فراهم میسازد. زمانی که خروجی مدل مستند به یک منبع مشخص است، قابلیت اعتماد و تحلیل آن برای سیستمهای سازمانی چندین برابر خواهد بود. این مزیت، زمینهساز تصمیمهای دقیقتر، مسئولانهتر و مبتنیبر شواهد است.
کاهش «Hallucination» در پاسخها
خطای hallucination، یعنی تولید پاسخهایی که ظاهراً منطقی اما در واقع نادرستاند، یکی از دغدغههای جدی در کاربرد LLMهاست. RAG با بهرهگیری از منابع خارجی و بازیابی اطلاعات واقعی، احتمال بروز چنین خطاهایی را بهطور محسوسی کاهش میدهد. این مسئله نهفقط اعتبار خروجی مدل را حفظ میکند، بلکه از بروز هزینههای ناشی از تصمیمگیری بر مبنای اطلاعات نادرست نیز جلوگیری خواهد کرد.
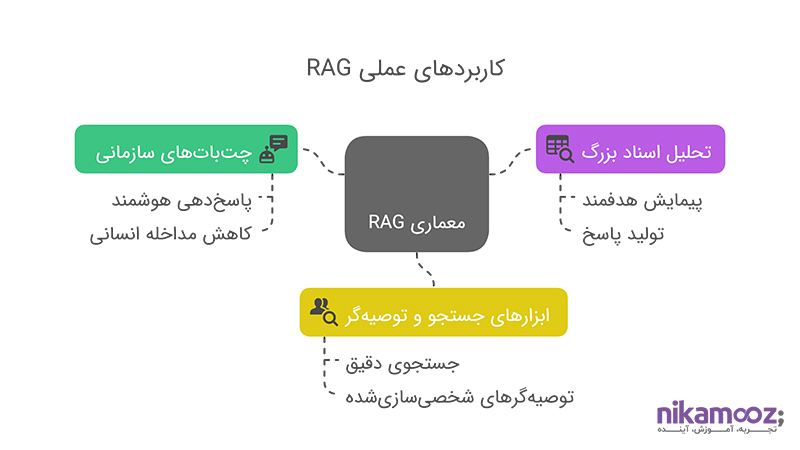
کاربردهای عملی RAG
معماری RAG بهعنوان یکی از پیشرفتهترین ساختارها در تلفیق یادگیری زبان و بازیابی اطلاعات، قابلیتهای گستردهای در کاربردهای واقعی و عملی دارد. این معماری زمانی بیشترین ارزش را ایجاد میکند که مسئله پاسخگویی دقیق، مبتنیبر داده و قابل اطمینان در میان باشد. در ادامه با سه مورد از مهمترین کاربردهای RAG در سامانههای پیشرفته آشنا میشویم.
📑
مطالعه بیشتر 👈 تشخیص چهره با هوش مصنوعی: از کاربرد تا نحوه عملکرد 📑
-
استفاده در چتباتهای سازمانی و پاسخدهی هوشمند
در محیطهایی که حجم داده زیاد است و پاسخهای دقیق، شفاف و مستند اهمیت دارند، استفاده از چتباتهای مجهز به RAG تحولآفرین است. برخلاف چتباتهای معمولی که فقط بر حافظه مدل تکیه میکنند، این نوع چتباتها میتوانند قبل از پاسخگویی، اطلاعات مرتبط را از منابع داخلی یا اسناد ساختیافته استخراج کرده و بر همان اساس، پاسخهایی دقیقتر و قابل اتکا ارائه دهند. چنین سیستمی قادر است به سؤالات پیچیدهتری پاسخ دهد، نیاز به مداخله انسانی را کاهش دهد و کیفیت تعاملات دیجیتال را بهشکل محسوسی افزایش دهد.
-
تحلیل اسناد بزرگ و بازیابی هدفمند اطلاعات
در بسیاری از پروژهها، نیاز به تحلیل و پاسخگویی بر اساس دادههایی حجیم و متنی وجود دارد. RAG با امکان اتصال به منابع بیرونی و تبدیل آنها به embedding قابل جستجو، میتواند اسناد بزرگ را بهصورت هدفمند پیمایش کند. سپس، با یافتن بخشهای مرتبط، از آنها بهعنوان ورودی برای تولید پاسخ استفاده کند. این سازوکار در موقعیتهایی مثل پاسخ به استعلامهای فنی، تحلیل گزارشهای پیچیده، یا پردازش آرشیوهای بزرگ بهشکل چشمگیری کارآمد است.
-
کاربرد RAG در ابزارهای جستجو و توصیهگر
سیستمهای جستجو و پیشنهاددهی، زمانی اثربخش هستند که هم زمینه کاربر را بفهمند و هم بتوانند پاسخ را هوشمندانه بازتولید کنند. RAG با ترکیب retrieval دقیق و generation شخصیسازیشده، بستری ایجاد میکند که خروجی نهتنها مرتبط با جستجو، بلکه متناسب با نیاز و بافت تعامل باشد. این ترکیب، عملکرد موتورهای جستجو و توصیهگرهای مدرن را به سطحی بالاتر از دقت، شخصیسازی و تفسیرپذیری میبرد.
اجزای اصلی معماری RAG
معماری RAG، برخلاف مدلهای سنتی که صرفاً بر تولید متن از روی دادههای آموزشدیده تکیه دارند، شامل دو مؤلفه کلیدی است که با همکاری یکدیگر امکان تولید پاسخهای دقیقتر، مستندتر و شخصیسازیشده را فراهم میکنند. شناخت عملکرد این اجزا، گام اول برای درک مزایای عملیاتی RAG در سیستمهای پاسخگو و پردازش زبان طبیعی محسوب میشود.
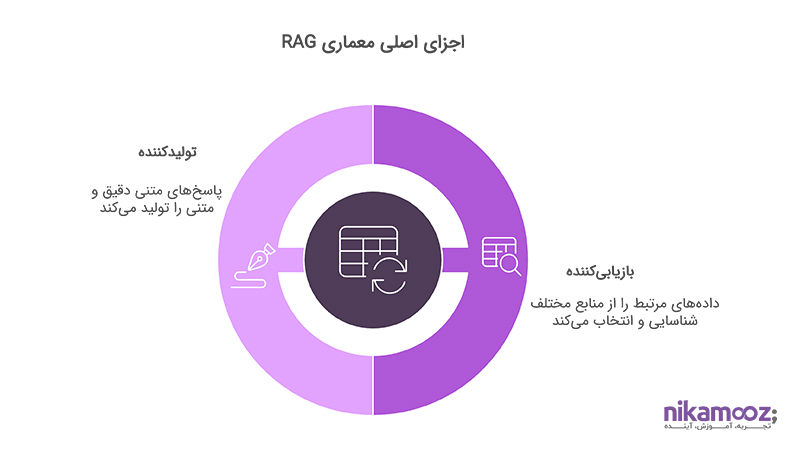
بازیابیکننده (Retriever)
بازیابیکننده، نقش دروازهبان اطلاعات را در معماری RAG ایفا میکند. وظیفه آن یافتن دادههای مرتبط با پرسش یا ورودی کاربر از بین منابع اطلاعاتی است. این منابع میتوانند پایگاههای داده ساختیافته، اسناد متنی، حافظه برداریشده (Vector Store) یا APIهای جستجو باشند. برای این کار، پرسش به بردار تبدیل میشود (Embedding) و با استفاده از الگوریتمهای شباهت، نزدیکترین اسناد انتخاب میشوند. ویژگی مهم این مؤلفه، استقلال آن از مدل زبانی اصلی است؛ بهعبارتی، میتوان از هر نوع موتور بازیابی پیشرفته (مانند ElasticSearch، FAISS یا Pinecone) در این بخش بهره گرفت. دقت، سرعت و تنوع نتایج بازیابیشده تأثیر مستقیمی بر کیفیت نهایی پاسخ دارد و به همین دلیل، طراحی صحیح این بخش نقشی کلیدی در عملکرد کل سیستم دارد.
تولیدکننده (Generator)
تولیدکننده وظیفه دارد بر اساس خروجی بازیابیکننده، پاسخی متنی تولید کند که هم از نظر معنایی دقیق باشد، هم بافت گفتوگو را حفظ کند، و هم منطبق با هدف کاربر باشد. این بخش معمولاً از یک مدل LLM استفاده میکند که قادر است اطلاعات ورودی را با زمینه تعاملات قبلی ترکیب کرده و خروجی نهایی را شکل دهد. نکته مهم در طراحی این بخش، توانایی مدل در استفاده صحیح از اطلاعات ارائهشده است. بهعبارتی، مدل باید بداند از کدام بخش داده بازیابیشده استفاده کند و چطور آن را در قالب زبانی روان، مستند و کاربردی ارائه دهد. اگر این هماهنگی بهدرستی انجام شود، خروجی نهایی نهتنها دقیق بلکه قابل اتکا و تفسیرپذیر خواهد بود.
📑
مطالعه بیشتر 👈 LLM چیست؟ هرآنچه باید درباره مدلهای زبانی بزرگ بدانید! 📑
مقایسه RAG با سایر معماریهای مشابه
در سالهای اخیر، رویکردهای مختلفی برای بهینهسازی عملکرد مدلهای زبانی بزرگ توسعه یافتهاند. معماری RAG بهعنوان یکی از موفقترین این روشها، مزایای مهمی نسبت به مدلهای دیگر ارائه میدهد؛ چه در دقت، چه در تفسیرپذیری، و چه در انعطافپذیری پیادهسازی. در این بخش، سه مقایسه کلیدی انجام میدهیم تا جایگاه RAG در میان معماریهای جایگزین روشنتر شود.

RAG در برابر مدلهای end-to-end بدون retrieval
در معماریهای end-to-end سنتی، مدل زبانی به تنهایی مسئول تمام فرآیند پاسخگویی است؛ از تحلیل پرسش گرفته تا تولید پاسخ. این رویکرد، گرچه سادهتر به نظر میرسد، اما بهشدت به حافظه درونی مدل و دادههای آموزشدیده محدود میشود. در نتیجه، احتمال بروز پاسخهای کلی، قدیمی یا نادرست بسیار بالاست. در مقابل، RAG با افزودن لایه بازیابی (retrieval) پیش از تولید پاسخ، امکان دسترسی به اطلاعات بهروز و زمینهمند را فراهم میکند. این فرآیند باعث میشود پاسخ نهایی، نه صرفاً محصول دانش قبلی مدل، بلکه حاصل تحلیل دادههای واقعی و مرتبط با درخواست باشد. بنابراین، RAG در سناریوهایی که دقت بالا، مستندسازی و بهروز بودن اطلاعات اهمیت دارد، گزینهای قابلاتکاتر است.
تفاوت RAG با Fine-Tuning سنتی
روش Fine-Tuning معمولی مبتنی بر بهروزرسانی وزنهای مدل با استفاده از مجموعهدادههای جدید است. این رویکرد در مواقعی که دسترسی به منابع محاسباتی بالا وجود دارد و دادهها بهطور منظم ساختیافتهاند، کارآمد است. اما در عمل، فرآیند زمانبر و پرهزینهای است و در برابر تغییرات سریع دانش، انعطافپذیری ندارد. در نقطه مقابل، RAG بدون نیاز به تغییر در ساختار مدل اصلی، میتواند از طریق بهروزرسانی منبع دادههای بازیابیشونده، خود را با شرایط جدید وفق دهد. بهبیان ساده، در RAG بهجای “آموزش مجدد مدل”، کافی است منابع دانش را بهروز کنید.
📑
مطالعه بیشتر 👈 NLP چیست؟ هر آنچه باید درباره پردازش زبان طبیعی بدانید! 📑
چرا RAG نسبت به chain-of-thought ساختار بهتری دارد؟
رویکرد chain-of-thought (زنجیره تفکر) تلاش میکند با افزودن مراحل استدلال به فرآیند تولید پاسخ، دقت مدل را افزایش دهد. گرچه این روش در برخی مسائل منطقی مفید است، اما باز هم متکی بر حافظه مدل است و به دادههای خارجی دسترسی ندارد. RAG از این جهت برتری دارد که علاوه بر استدلال زبانی، اطلاعات واقعی را نیز وارد چرخه پاسخگویی میکند. این ترکیب، قدرت تحلیل chain-of-thought را با واقعگرایی retrieval ترکیب میکند. در نتیجه، خروجی مدل نهفقط دقیقتر، بلکه مستندتر و معتبرتر خواهد بود.
سخن پایانی
معماری RAG پاسخی منطقی و موثر به یکی از بزرگترین چالشهای مدلهای زبانی بزرگ است: تولید پاسخهایی دقیق، قابل استناد و متناسب با زمینه. ترکیب retrieval و generation در یک ساختار منسجم، این امکان را فراهم کرده که مدل نهتنها از حافظه آموزشدیده خود استفاده کند، بلکه بتواند به دادههای بیرونی و بهروز نیز متکی باشد. در این مقاله دیدیم که RAG چگونه دقت خروجی مدلهای زبانی را افزایش میدهد، چطور خطاهای hallucination را کاهش میدهد و در چه کاربردهایی مثل چتباتهای سازمانی، تحلیل اسناد، یا ابزارهای توصیهگر، مزیت رقابتی ایجاد میکند. همچنین تفاوتهای آن با روشهایی مثل fine-tuning سنتی یا chain-of-thought بررسی شد تا مشخص شود چرا RAG برای بسیاری از سیستمهای مدرن، انتخابی مطمئنتر و آیندهنگرانهتر است. در نهایت، RAG فقط یک معماری جدید نیست؛ بلکه پاسخی است به نیاز به دادهمحوری، دقت، و تفسیرپذیری در پاسخگویی هوشمند؛ در صورتی که به دنبال راهکارهای حرفهای و قابلاعتماد برای کسبوکار خود هستید، همکاری با نیک آموز میتواند نقطه شروع تحول باشد.
سوالات متداول
1. آیا RAG فقط برای زبان انگلیسی کاربرد دارد؟
خیر. در حالی که اغلب پیادهسازیهای اولیه برای زبان انگلیسی توسعه یافتهاند، معماری RAG با استفاده از موتورهای بازیابی و مدلهای زبانی چندزبانه، قابلیت گسترش به زبانهای دیگر را نیز دارد. شرط اصلی، وجود embedding مناسب و منابع داده معتبر به آن زبان است.
2. چه زمانی استفاده از RAG بهتر از مدلهای زبانی معمولی است؟
زمانی که دقت بالا، استناد به منابع واقعی و کاهش خطای پاسخ اهمیت دارد. مثلاً در سیستمهای چتبات سازمانی، تحلیل اسناد یا پاسخ به سوالات مبتنی بر دادههای خاص، استفاده از RAG میتواند کیفیت نتایج را بهطور محسوسی بهبود دهد.
3. آیا RAG جایگزین Fine-Tuning سنتی شده است؟
در بسیاری از کاربردها بله. معماری RAG امکان بهروزرسانی اطلاعات از طریق منابع خارجی را فراهم میکند، بدون نیاز به آموزش مجدد مدل. این یعنی در شرایطی که سرعت، انعطافپذیری و بهروز بودن اهمیت دارند، RAG نسبت به Fine-Tuning روشی کاراتر محسوب میشود.