
در دنیایی که هر کلیک، خرید، پیام یا تراکنش بهنوعی داده تولید میکند، این سؤال مهمتر از همیشه است: چطور میتوان از این حجم عظیم داده، اطلاعات مفید استخراج کرد؟ اینجاست که مفهومی به نام دادهکاوی (Data Mining) وارد میدان میشود.
دادهکاوی، فرآیندی تحلیلیست که با استفاده از الگوریتمها، الگوها و روشهای خاص، به کشف دانش پنهان در میان انبوه دادهها کمک میکند. مفهومی که شاید در نگاه اول پیچیده به نظر برسد، اما در عمل، یکی از بنیادیترین ابزارهای تصمیمگیری هوشمند در سازمانها و سیستمهای اطلاعاتی پیشرفته است.
در این مقاله بهطور کامل بررسی میکنیم که داده کاوی چیست، چه تفاوتی با تحلیل داده و یادگیری ماشین دارد، چه کاربردهایی در دنیای واقعی دارد و چرا امروز بیشتر از همیشه به آن نیاز داریم.
داده کاوی چیست؟
دادهکاوی (Data Mining) به فرآیند کشف الگوها، روابط و دانش پنهان در دادههای حجیم و پیچیده گفته میشود؛ آنهم با استفاده از الگوریتمها، تکنیکهای آماری، و روشهای یادگیری ماشین. این فرآیند، به کسب اطلاعات ارزشمند از دل دادههایی کمک میکند که در ظاهر پراکنده و بیساختار به نظر میرسند.
برخلاف تصور عمومی، دادهکاوی تنها به جمعآوری داده محدود نمیشود. بلکه شامل تحلیل عمیق دادهها، شناسایی الگوهای تکرارشونده، پیشبینی روندها و تصمیمگیری مبتنی بر شواهد است. در واقع، دادهکاوی پلی است میان دادههای خام و تصمیمات هوشمند.
دادهکاوی بخشی از مجموعه بزرگتری به نام علم داده (Data Science) است که با استفاده از تکنیکهایی مانند خوشهبندی (Clustering)، طبقهبندی (Classification)، کشف قواعد انجمنی (Association Rules) و تحلیل پیشبینانه، ارزش واقعی دادهها را نمایان میکند.
اگر بخواهیم خلاصه کنیم، دادهکاوی پاسخی است به این نیاز بنیادین: چگونه از میان حجم عظیم دادهها، به اطلاعاتی دست پیدا کنیم که به عمل منتهی شوند؟
برای اطلاعات بشتر و درخواست مشاوره رایگان از خدمات کلان داده نیک آموز به صفحه اختصاصی آن مراجعه کنید.
کاربردهای دادهکاوی در صنایع مختلف
با رشد بیوقفه دادهها در سازمانها، ارزش واقعی دادهکاوی زمانی آشکار میشود که نتایج آن در فرآیندهای عملیاتی و تصمیمسازیهای حیاتی استفاده شوند. از سیستمهای مالی تا فروشگاههای آنلاین و از مراکز درمانی تا پلتفرمهای اجتماعی، دادهکاوی با شناخت دقیق الگوها، سودآوری، بهرهوری و امنیت را در سطحی جدید تعریف میکند.
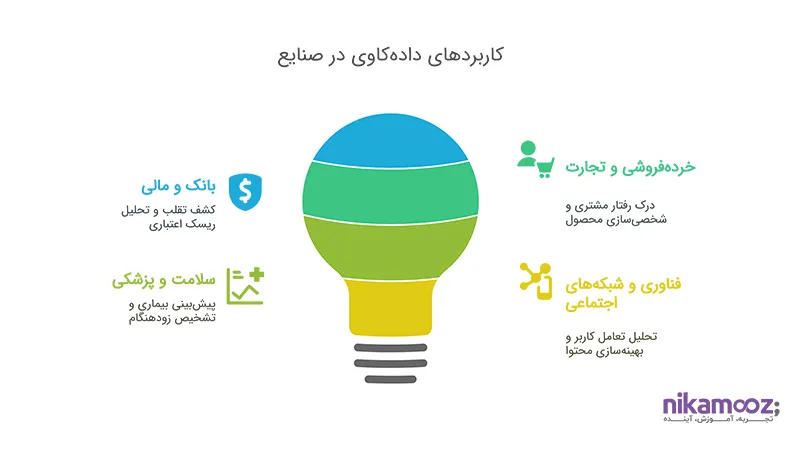
کاربرد در حوزه بانک و مالی
در صنعت مالی، تصمیمها باید بر پایه دقت، سرعت و پیشبینی آینده باشند. دادهکاوی در این حوزه با:
- کشف تقلبهای مالی در تراکنشها.
- تحلیل ریسک اعتباری مشتریان.
- شخصیسازی خدمات مالی بر اساس الگوهای رفتاری.
نقش تعیینکنندهای دارد. بهعنوان مثال، الگوریتمهای طبقهبندی و تشخیص ناهنجاری میتوانند الگوهای غیرعادی را شناسایی کنند و جلوی وقوع کلاهبرداریهای پیچیده را بگیرند — پیش از آنکه خسارت وارد شود.
کاربرد در خردهفروشی و تجارت
در فضای رقابتی بازار، درک رفتار مشتری دیگر یک مزیت نیست، بلکه یک ضرورت است. دادهکاوی در این صنعت کمک میکند تا:
- الگوهای خرید مشتریان کشف شود.
- پیشنهادات محصول شخصیسازی گردد.
- محصولات پرفروش یا کمسود شناسایی شوند.
یکی از رایجترین پروژههای data mining در این حوزه، تحلیل سبد خرید مشتری (Basket Analysis) است که به درک ارتباط بین محصولات کمک میکند. ( مثلاً اینکه خرید پنیر ممکن است به خرید نان منجر شود.)
کاربرد در صنعت سلامت و پزشکی
در پزشکی، دادهکاوی میتواند جان نجات دهد. از طریق تحلیل دادههای کلینیکی و پروندههای پزشکی:
- پیشبینی بیماریها و ریسک بیماران.
- تحلیل اثربخشی داروها و پروتکلهای درمانی.
- تشخیص زودهنگام اختلالات پیچیده.
امکانپذیر میشود. پروژههایی مثل دادهکاوی در تصاویر پزشکی یا تحلیل نتایج آزمایشگاهی، یکی از کاربردهای مهم این فناوری در حوزه سلامت است.
کاربرد در فناوری و شبکههای اجتماعی
پلتفرمهای اجتماعی، معدن طلایی از دادههای رفتاری کاربران هستند. دادهکاوی در این فضا:
- الگوهای تعامل کاربران را کشف میکند.
- محتوای مرتبط و شخصیسازیشده ارائه میدهد.
- موجب شناسایی کاربران فعال، ریزش یا کاربران تأثیرگذار میشود.
با کمک الگوریتمهای خوشهبندی یا تحلیل احساسات (Sentiment Analysis)، میتوان رفتار کاربران را تحلیل و تجربه کاربری را بهینه کرد؛ حتی پیش از آنکه کاربر واکنشی نشان دهد.
انواع دادهکاوی (بر اساس هدف و روش)
یکی از مهمترین دستهبندیها در حوزه دادهکاوی (Data Mining)، تفکیک آن بر اساس هدف نهایی تحلیل و نوع خروجی مورد انتظار است. شناخت این دستهها به درک بهتر از کاربرد دادهکاوی در پروژههای واقعی کمک میکند و نشان میدهد که چگونه از دادهها برای پاسخ به پرسشهای متفاوت استفاده میشود.
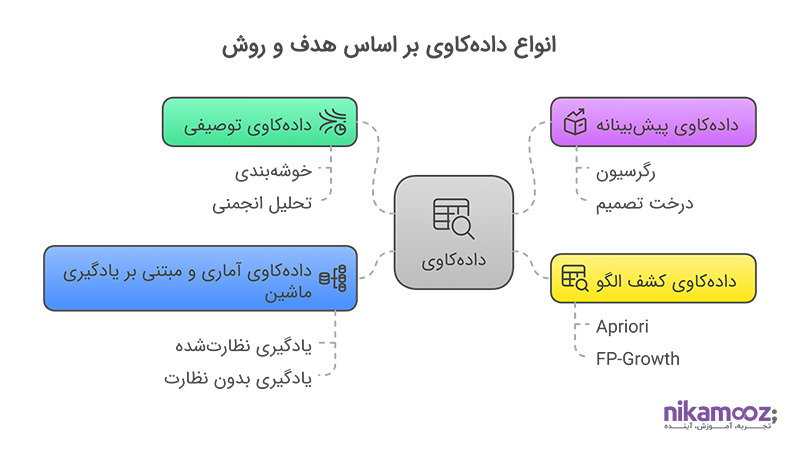
در ادامه، چهار نوع رایج و بنیادین دادهکاوی را بررسی میکنیم:
دادهکاوی توصیفی
این نوع دادهکاوی، بر تحلیل گذشته تمرکز دارد. هدف آن، شرح وضعیت فعلی یا تاریخی دادهها با کشف الگوهای قابلمشاهده و قابلتوصیف است.
در این رویکرد، سؤالاتی از این جنس مطرح میشود:
- مشتریان وفادار چه ویژگیهایی دارند؟
- پراکندگی فروش در مناطق مختلف چگونه است؟
ابزارهای خوشهبندی (Clustering)، تحلیل انجمنی (Association Rules) و توزیع آماری معمولاً در دادهکاوی توصیفی استفاده میشوند. نتیجه این نوع تحلیلها، گزارشها و داشبوردهایی هستند که اطلاعات گذشته را با ساختار قابل فهم نمایش میدهند.
دادهکاوی پیشبینانه
در مقابل دادهکاوی توصیفی، این نوع تحلیل تلاش میکند بر اساس دادههای موجود، رویدادهای آینده را پیشبینی کند.
به عنوان مثال:
- آیا این مشتری احتمالاً در ماه آینده خرید خواهد کرد؟
- خطر پیشفرض در بازپرداخت یک وام چقدر است؟
مدلهایی مانند رگرسیون، درخت تصمیم، شبکههای عصبی مصنوعی و ماشین بردار پشتیبان (SVM) در این حوزه کاربرد زیادی دارند. این نوع دادهکاوی، اغلب پایه اصلی سیستمهای تصمیمیار، پیشبینی فروش، و تحلیل رفتار کاربر است.
دادهکاوی کشف الگو
اینجا تمرکز بر کشف روابط پنهان و قوانین تکرارشونده در دادههاست، بدون آنکه هدف مشخصی از پیش تعیین شده باشد. این نوع دادهکاوی میتواند الگوهایی را استخراج کند که تحلیلگر حتی از وجود آنها آگاه نبوده است.
برای مثال:
- همزمانی خرید محصولات خاص (Basket Analysis).
- کشف زنجیره رفتارهای کاربران در وبسایت.
الگوریتمهایی مانند Apriori یا FP-Growth در این حوزه استفاده میشوند و پایه بسیاری از پروژههای دادهکاوی در بازاریابی، سیستمهای توصیهگر و تحلیل سبد خرید هستند.
دادهکاوی آماری و مبتنی بر یادگیری ماشین
در بسیاری از پروژهها، دادهکاوی با مدلهای آماری و الگوریتمهای یادگیری ماشین ترکیب میشود تا تحلیلهای دقیقتری ارائه دهد. این ترکیب باعث میشود دادهکاوی از مرحله توصیف و پیشبینی عبور کند و به سمت تصمیمسازی خودکار، تشخیص الگوهای پیچیده و بهینهسازی مستمر سیستمها حرکت کند.
این دسته شامل:
- الگوریتمهای یادگیری نظارتشده (Supervised Learning).
- یادگیری بدون نظارت (Unsupervised Learning).
- و مدلهای مبتنی بر احتمالات آماری.
در اینجا، دادهکاوی نهتنها اطلاعات تولید میکند، بلکه بهعنوان یک عنصر فعال در خودکارسازی تصمیمگیریها نقش ایفا میکند. (مخصوصاً در سیستمهای مقیاسپذیر و دارای جریان دادههای پیوسته.)
مراحل داوه کاوی
دادهکاوی فقط اجرای الگوریتمها و تحلیل دادهها نیست؛ بلکه فرآیندی ساختاریافته است که از درک مسئله آغاز میشود و تا استقرار راهکار و یادگیری مستمر ادامه پیدا میکند. یکی از استانداردترین چارچوبها برای اجرای پروژههای دادهکاوی، مدل (CRISP-DM (Cross Industry Standard Process for Data Mining است که شامل شش مرحله کلیدی زیر میشود:
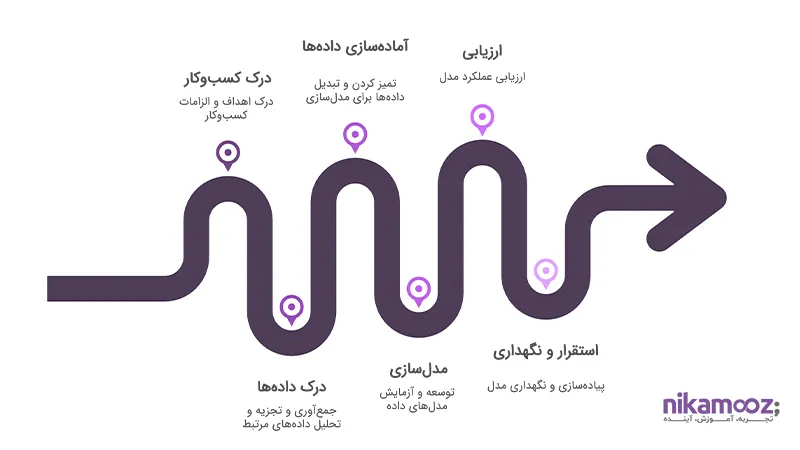
1- درک کسبوکار (Business Understanding)
شروع هر پروژه دادهکاوی موفق، نه با داده، بلکه با درک دقیق از اهداف کسبوکار آغاز میشود. این مرحله، پایهگذار کل مسیر پروژه است؛ جایی که باید مشخص شود مسئله اصلی چیست، چرا اهمیت دارد و چه خروجیای از آن انتظار میرود.
گاهی مسئله در ظاهر ساده به نظر میرسد، مانند کاهش فروش یا افزایش ریزش مشتری؛ اما تحلیل درست نیازمند درک عمیقتر از بستر تجاری موضوع است. تعریف دقیق مسئله، شناسایی اولویتها و تعیین شاخصهای موفقیت، سه جزء کلیدی این مرحلهاند.
در همین مرحله، محدودیتهای موجود هم بررسی میشود: آیا دادهها بهروز هستند؟ آیا دسترسی به منابع داده امکانپذیر است؟ اگر پاسخ این پرسشها روشن نباشد، پروژه ممکن است از ابتدا منحرف شود.
2- درک دادهها (Data Understanding)
پس از تعیین هدف، نوبت به بررسی دقیق دادهها میرسد. در این مرحله، تحلیلگر تلاش میکند ساختار، کیفیت، نوع و توزیع دادهها را درک کند و بفهمد آیا این دادهها پاسخگوی مسئله تعریفشده هستند یا نه.
اقداماتی مثل تحلیل آماری اولیه، کشف مقادیر گمشده، بررسی ناهنجاریها و رسم نمودارهای توصیفی، از اجزای کلیدی این گام هستند. همچنین شناسایی منابع داده (مثلاً دیتابیس داخلی، فایلهای اکسل یا APIها) و نوع دادهها (عددی، متنی، طبقهای) به تصمیمگیری در مراحل بعد کمک میکند.
بدون شناخت کافی از دادهها، انتخاب مدل و روش تحلیل میتواند نادرست و پرهزینه باشد. این مرحله، پلی است بین هدف کسبوکار و اجرا.
3- آمادهسازی دادهها (Data Preparation)
بیشترین زمان در پروژههای دادهمحور، در همین مرحله صرف میشود. هدف این مرحله تبدیل دادههای خام به فرمی است که برای مدلسازی مناسب باشد.
اقداماتی نظیر پاکسازی دادههای ناقص یا تکراری، نرمالسازی مقادیر، مهندسی ویژگیها (Feature Engineering)، تبدیل متغیرهای متنی به عددی، و یکپارچهسازی دادهها از منابع مختلف، همگی در این مرحله انجام میشوند؛ یک اشتباه در این بخش میتواند منجر به نتایج تحلیلی نادرست یا حتی فاجعهآمیز شود. آمادهسازی دقیق، پایهای است که موفقیت مدلسازی را تضمین میکند.
4- مدلسازی (Modeling)
در این مرحله، با استفاده از الگوریتمهای تحلیلی و یادگیری ماشین، تلاش میشود مدلی ساخته شود که بتواند پاسخگوی مسئله تعریفشده باشد.
انتخاب مدل بر اساس نوع داده، هدف تحلیل و پیچیدگی مسئله انجام میشود. برای مثال، در تحلیل دستهبندی ممکن است از درخت تصمیم یا Random Forest استفاده شود، و در تحلیل پیشبینی از رگرسیون یا شبکههای عصبی.
در این مرحله، تقسیمبندی دادهها به آموزش (Training) و آزمون (Test)، تنظیم پارامترهای مدل (Hyperparameters)، و اعتبارسنجی متقابل (Cross Validation) از اهمیت بالایی برخوردارند. مدل باید نهتنها دقیق باشد، بلکه قابلتعمیم به دادههای واقعی نیز باشد.
5- ارزیابی (Evaluation)
هیچ مدلی بدون ارزیابی معتبر نیست. در این مرحله، عملکرد مدل از دو جنبه بررسی میشود:
- دقت آماری: با معیارهایی مانند Accuracy، Precision، Recall یا RMSE برای مدلهای پیشبینی
- تناسب با هدف کسبوکار: آیا خروجی مدل واقعاً در تصمیمگیری کمک میکند؟
در این مرحله، ممکن است چند مدل با هم مقایسه شوند یا مدل فعلی بازتنظیم شود. اگر نتایج قابلقبول نباشد، برگشت به مراحل قبل (مثلاً آمادهسازی یا مدلسازی) طبیعی است. مهم این است که مدل، تنها به اعداد دقیق نباشد — بلکه مفید، قابلفهم و قابلاستفاده هم باشد.
6- استقرار و نگهداری (Deployment)
در نهایت، مدل ساختهشده باید وارد چرخه عملیاتی شود. این یعنی یا در قالب یک داشبورد، یا یک API یا ماژول تحلیلی در سیستمهای واقعی سازمان پیادهسازی گردد؛ در این مرحله، مهم است که خروجی تحلیل برای تصمیمگیرندگان قابلاستفاده باشد. اگر خروجی مدل صرفاً بهصورت فنی ارائه شود، ممکن است کاربرد واقعی خود را از دست بدهد.
همچنین، پایش عملکرد مدل در طول زمان (Monitoring)، بهروزرسانی مدلها با دادههای جدید، و مستندسازی کامل فرآیند، از اجزای کلیدی نگهداری موفق یک پروژه دادهکاوی هستند. هدف نهایی این است که مدل، نهفقط در زمان ساخت، بلکه در بلندمدت نیز ارزشآفرین باقی بماند.
مثالهایی واقعی از پروژههای Data Mining
دادهکاوی زمانی معنا پیدا میکند که نتایج آن به حل یک مسئله واقعی منجر شود. در این بخش، به سه نمونه کاربردی و رایج از پروژههای data mining در فضای سازمانی میپردازیم که هرکدام نشان میدهند چگونه تحلیل هوشمند دادهها میتواند تصمیمسازی را متحول کند.
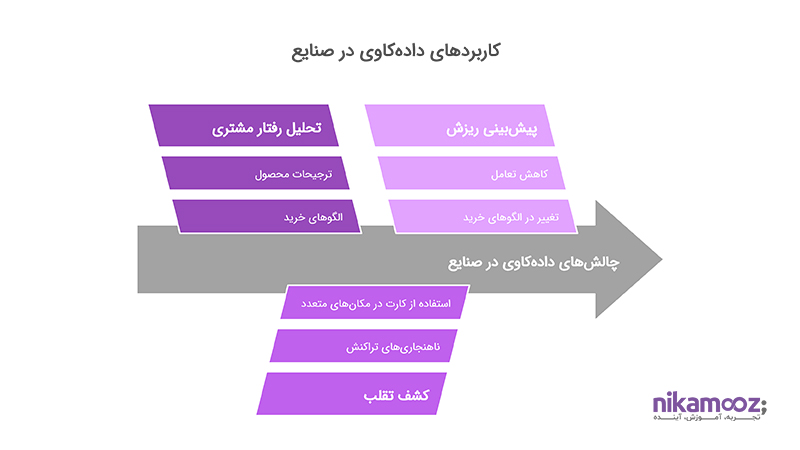
- تحلیل رفتار خرید مشتری
یکی از شناختهشدهترین کاربردهای دادهکاوی، تحلیل رفتار خرید مشتریان است. در این پروژهها، الگوهای خرید در بازههای زمانی مختلف، ترجیحات محصول، نرخ بازگشت، و زمانبندی خریدها بررسی میشود تا درک عمیقتری از نیازهای پنهان مشتریان بهدست آید.
برای مثال، یک فروشگاه زنجیرهای میتواند با بررسی دادههای مربوط به سبد خرید، متوجه شود که مشتریانی که لبنیات خاصی میخرند، معمولاً در همان بازه زمانی نان خاصی هم خرید میکنند. با استفاده از الگوریتمهای کشف قوانین انجمنی (Association Rules) مانند Apriori، این ارتباطها استخراج میشود.
خروجی چنین پروژهای میتواند به طراحی بهتر تخفیفها، بستهبندیهای پیشنهادی و حتی چیدمان قفسهها منجر شود. در دنیای دیجیتال، این تحلیل به سیستمهای توصیهگر (Recommendation Systems) تبدیل شده که در فروشگاههای اینترنتی دیده میشود: «افرادی که این محصول را خریدند، به آن محصول هم علاقهمند بودند.»
- کشف تقلب در تراکنشهای بانکی
در صنایع مالی، کشف تقلب (Fraud Detection) یکی از حساسترین و حیاتیترین کاربردهای دادهکاوی است. این پروژهها با هدف شناسایی فعالیتهای غیرمعمول در تراکنشهای بانکی انجام میشوند تا از وقوع کلاهبرداریهای مالی پیش از بروز خسارت جلوگیری شود.
برای مثال، اگر یک کارت بانکی بهطور همزمان در دو کشور مختلف استفاده شود، یا اگر الگوی تراکنشها بهطور ناگهانی تغییر کند، سیستم باید این رفتار را بهعنوان مشکوک شناسایی کند. برای این منظور، از الگوریتمهای تشخیص ناهنجاری (Anomaly Detection) و یادگیری غیرنظارتی (Unsupervised Learning) استفاده میشود.
پروژههای موفق در این حوزه، نهتنها بر اساس دادههای تاریخی آموزش میبینند، بلکه قابلیت تحلیل بلادرنگ (Real-time Detection) را هم دارند. بانکها و فینتکها از این قابلیتها برای ایجاد هشدارهای فوری، مسدودسازی موقت و بررسی انسانی تراکنشها استفاده میکنند.
- پیشبینی نرخ ریزش کاربران (Churn Prediction)
در بسیاری از صنایع، نگهداشت مشتری از جذب مشتری جدید مهمتر و کمهزینهتر است. اینجاست که پیشبینی ریزش کاربران (Churn Prediction) بهعنوان یکی از پروژههای کلیدی دادهکاوی مطرح میشود.
در چنین پروژههایی، رفتار مشتریانی که در گذشته سرویس را ترک کردهاند با رفتار مشتریان فعلی مقایسه میشود تا الگوهای مشترک و هشداردهنده شناسایی شوند. این میتواند شامل کاهش تدریجی تعامل، تغییر در الگوی خرید، یا افزایش تماس با پشتیبانی باشد.
الگوریتمهایی مثل درخت تصمیم، رگرسیون لجستیک، و XGBoost در این پروژهها پرکاربرد هستند. هدف این تحلیلها، ساخت مدلیست که بتواند کاربرانی را که در آستانه ریزش هستند شناسایی کرده و هشدار لازم را به موقع صادر کند.
با اطلاع از اینکه چه کسانی ممکن است سرویس را ترک کنند، تیمهای بازاریابی و خدمات میتوانند اقدامات پیشگیرانهای مانند ارسال پیشنهاد ویژه، تماس شخصی یا ارائه مزایای اختصاصی را اجرا کنند.
تفاوت دادهکاوی با مفاهیم مشابه
در این بخش از مقاله عمده تفاوت های دادهکاوی با مفاهیم مشابه را برای شما بازگو خواهیم کرد:
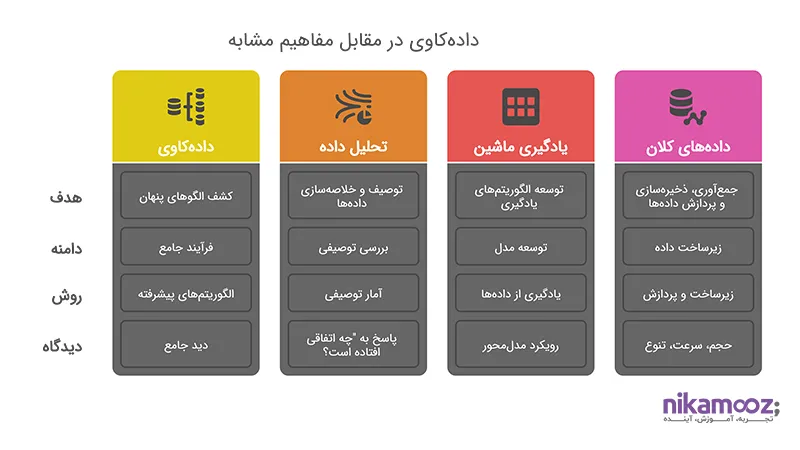
- تفاوت Data Mining با Data Analysis:
در نگاه اول، دادهکاوی و تحلیل داده تفاوت چندانی ندارند؛ هر دو به دنبال استخراج اطلاعات از دادهها هستند. اما در عمل، این دو مفهوم در هدف، روش و عمق تحلیل با هم تفاوت دارند.
Data Analysis بیشتر بر بررسی توصیفی دادهها تمرکز دارد؛ یعنی مشاهده، توصیف و خلاصهسازی اطلاعات برای پاسخ به سؤالات مشخص. ابزارهایی مانند Excel، آمار توصیفی و گزارشهای ساده در این حوزه کاربرد زیادی دارند؛ در مقابل، Data Mining یک مرحله جلوتر میرود. هدف در دادهکاوی، کشف الگوهای پنهان، ارتباطات پیچیده و پیشبینی اتفاقات آینده است. این کار معمولاً با استفاده از الگوریتمهای پیشرفتهتر و حجم دادهی بیشتر انجام میشود.
به بیان ساده، تحلیل داده پاسخ میدهد «چه اتفاقی افتاده؟»، اما دادهکاوی میپرسد «چرا افتاده؟ و در آینده چه خواهد شد؟»
- تفاوت Data Mining با Machine Learning:
دادهکاوی و یادگیری ماشین رابطه نزدیکی دارند، اما تفاوت آنها در دامنه کاربرد، هدفگذاری و سطح خودکارسازی نهفته است.
Data Mining یک فرآیند جامع است که از شناسایی مسئله گرفته تا آمادهسازی داده، اجرای مدل و تفسیر نتایج را در بر میگیرد. الگوریتمهای یادگیری ماشین یکی از ابزارهای مورد استفاده در این مسیر هستند؛ اما Machine Learning بیشتر به معنای توسعه الگوریتمهاییست که بتوانند از دادهها یاد بگیرند و بدون برنامهنویسی صریح، عملکرد خود را بهبود دهند. تمرکز یادگیری ماشین روی خود مدل است — نه کل چرخه تحلیل.
دادهکاوی ممکن است از یادگیری ماشین استفاده کند، اما شامل مراحل بیشتری مانند تحلیل کسبوکار، درک دادهها و ارزیابی نهایی است. از این نظر، دادهکاوی دیدگاه کلنگر دارد، در حالی که یادگیری ماشین رویکردی مدلمحور و خودکار دارد.
- تفاوت Data Mining با Big Data:
درک تفاوت میان دادهکاوی و کلانداده (Big Data) معمولاً به شناخت درست از ابعاد داده کمک میکند. برخلاف تصور رایج، این دو بههیچوجه مترادف نیستند.
Big Data اشاره به مجموعه دادههایی دارد که از نظر حجم، سرعت و تنوع بسیار بالا هستند — بهطوریکه روشهای سنتی قادر به پردازش آنها نیستند. هدف در اینجا بیشتر جمعآوری، ذخیرهسازی و پردازش این دادهها با زیرساختهای مناسب است؛ در مقابل، Data Mining به ابزارها و روشهایی اشاره دارد که برای تحلیل این دادهها بهکار میروند — صرفنظر از حجم آنها. بهعبارت دیگر، Big Data ظرف است و دادهکاوی محتوا.
ممکن است پروژهای بدون Big Data هم از دادهکاوی استفاده کند. اما در پروژههای کلانداده، استفاده از دادهکاوی برای استخراج ارزش از دل انبوه اطلاعات، یک ضرورت محسوب میشود.
چطور میتوان یک پروژه دادهکاوی را آغاز کرد؟
شروع یک پروژه دادهکاوی، فراتر از انتخاب ابزار یا اجرای چند الگوریتم است. این مسیر باید با هدفگذاری روشن، برنامهریزی دقیق، و همراستاسازی کامل با مسائل واقعی سازمان آغاز شود.
نخستین گام، تعریف دقیق مسئلهای است که قرار است حل شود. آیا قصد داریم رفتار مشتریان را تحلیل کنیم؟ یا بهدنبال کشف تقلب در تراکنشها هستیم؟ بدون درک درست از نیاز واقعی، حتی دقیقترین مدلها هم نمیتوانند ارزشآفرین باشند.
در ادامه، کیفیت و ساختار دادههای موجود بررسی میشود. بسیاری از پروژهها دقیقاً در همین نقطه متوقف میشوند: یا دادهها ناقصاند، یا ساختار مناسب برای مدلسازی ندارند. اگر این گام نادیده گرفته شود، اجرای فنی عملاً بیاثر خواهد بود.
با عبور از این مرحله، میتوان مسیر اجرای پروژه را طراحی کرد؛ از انتخاب ابزارهای مناسب (مانند Python یا Power BI) تا آمادهسازی داده و ساخت مدلهای تحلیلی. اما چیزی که اغلب نادیده گرفته میشود، نیاز به تجربه عملی در مواجهه با چالشهای واقعی پروژههاست.
اینجاست که همکاری با تیمهایی که نهفقط آموزش ابزارها، بلکه تجربه اجرای پروژههای دادهکاوی در سازمانهای مختلف را دارند، به یک مزیت راهبردی تبدیل میشود.
در همین مسیر، نیک آموز با تمرکز همزمان بر آموزش تخصصی و اجرای پروژههای واقعی، میتواند نقشی کلیدی ایفا کند؛ از طراحی ساختار داده تا استقرار مدل در بستر عملیاتی. این نوع مشارکت، احتمال موفقیت پروژه را نهتنها افزایش میدهد، بلکه به تصمیمگیری دقیقتر، سریعتر و کمهزینهتر منجر میشود.
سخن پایانی
با گسترش روزافزون دادهها در سازمانها، نیاز به روشهایی برای استخراج دانش از دل اطلاعات خام، بیش از هر زمان دیگری احساس میشود. دادهکاوی بهعنوان یک ابزار تحلیلی پیشرفته، نهتنها امکان درک بهتر از وضعیت فعلی را فراهم میکند، بلکه توانایی پیشبینی آینده و خلق مزیت رقابتی را در اختیار تصمیمسازان قرار میدهد.
در این مقاله بررسی شد که دادهکاوی چیست، چه تفاوتی با مفاهیم مشابه دارد، چگونه اجرا میشود و در چه صنایع و سناریوهایی بیشترین اثر را دارد. همچنین به مراحل اجرایی یک پروژه دادهکاوی، ابزارهای مورد استفاده، و روندهای آیندهمحور آن پرداختیم.
اما دادهکاوی صرفاً یک دانش فنی نیست؛ بلکه فرهنگ تصمیمگیری مبتنی بر داده است. سازمانهایی که بتوانند این فرهنگ را بهدرستی نهادینه کنند، در رقابتهای آینده، نه با حدس و گمان، بلکه با تحلیل، سرعت و دقت پیش خواهند رفت.
نیک آموز با تجربه اجرای پروژههای موفق، آماده ارائه راهکارهای اختصاصی برای سازمانها و شرکتهای پیشرو است.
سوالات متداول دادهکاوی
1. Data Mining چه تفاوتی با Machine Learning دارد؟
دادهکاوی (Data Mining) یک فرآیند جامع برای کشف الگوها، روابط و دانش پنهان در دادههاست که از مرحله درک مسئله تا آمادهسازی داده و تحلیل خروجی را شامل میشود. در مقابل، یادگیری ماشین (Machine Learning) به توسعه مدلهایی میپردازد که میتوانند از دادهها یاد بگیرند و بدون برنامهنویسی مستقیم، پیشبینی انجام دهند.
2. آیا دادهکاوی فقط برای سازمانهای بزرگ کاربرد دارد؟
خیر. تصور اینکه دادهکاوی فقط برای سازمانهای بزرگ کاربرد دارد، یک برداشت اشتباه رایج است. در واقع، دادهکاوی برای هر کسبوکاری که داده دارد و میخواهد تصمیمات دقیقتری بگیرد، قابل استفاده است؛ صرفنظر از اندازه سازمان.
3. چه ابزارهایی برای شروع دادهکاوی مناسب هستند؟
ابزارهایی مانند Python ، RapidMiner، Power BI و R جزو گزینههای رایج هستند. انتخاب ابزار به پیچیدگی پروژه و مهارت تیم بستگی دارد.